Evaling llm-jp-eval (evals are hard)
With training of shisa-v2 starting in earnest, I’ve been digging a bit more into llm-jp-eval, which I used as a quick and simple benchmark to help to track shisa-v1 (especially the base model) performance during development.
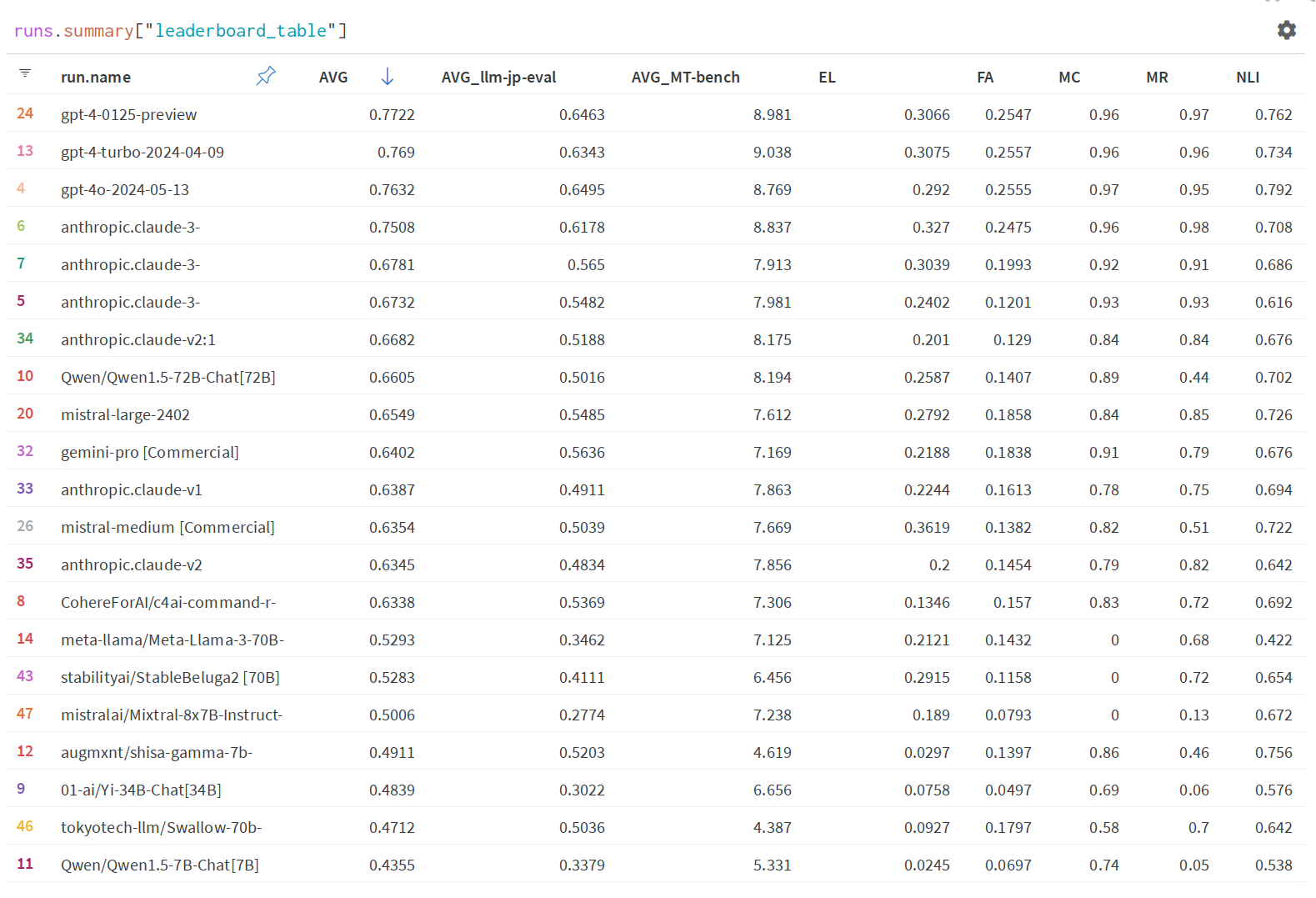
WandB has implement the Nejumi LLM Leaderboard which has a test harness for modifying settings and uploading/viewing on WandB (here’s my workspace: https://wandb.ai/augmxnt/nejumi).
First I was curious to see if I could replicate the shisa-gamma-7b-v1 results, which despite (IMO) being superceded by generally stronger JA models, still actually ranks at the top of the JA-tuned open models. But if you look for shisa-7b-v1 you’ll find that it basically does not complete. These models are basically tuned on the same dataset, so what’s going on exactly?
Well, for the second part, that’s actually relatively easy to answer. Both the base model and final shisa-7b were trained requiring a bos_token (see note) and it simply won’t output sensible output without it. You can see that when using a config with the default prompt with a bos_token prepended, it scores almost as well as shisa-gamma-7b-v1.
Now as for untangling the other mystery - surprisingly, when testing with the native (llama2) chat template, it actually performs much worse. Why is this? Well, let’s look at the output. It turns out that when you use the Japanese prompt… the model tends to want to answer in Japanese:

This is significantly less likely to happen when not using fine-tuned chat formatting (and it reverts to act as more of a base model). As logprobs aren’t used, well, if you reply in Japanese, the scores are a big fat zero on those benchmarks. I did some clicking around and found this and other “formatting” related correctness issues to be prevalent as many of the scores collected are exact match scores (this is important because below a certain size/capability level, LLMs will be pretty brittle; also fine-tuning for single word answers tends to destroy general performance for smaller models). Let’s just dive in to one example.
If you order on the Nejumi Leaderboard by JA MT-Bench scores, you can see Lightblue’s lightblue/qarasu-14B-chat-plus-unleashed is the top scoring JA open model for MT-Bench, but it has a relatively abysmal 0.1437 on the llm-jp-eval. WandB has info on all the runs they’ve done as well, so clicking in, let’s take a look. This model scores straight 0’s on many tests/categories. Let’s see for janli:

Here it’s returning Japanese, not English. How about for jcommonsense?

This requires more checking, but I believe it has to be a parsing error… And how about mawps_exact?

OK, well, looks like Qarasu is not the best at math, but even when it does get the right answer, it still gets a 0, since it’s scored as an exact match of only a number as an answer. I mean, maybe this tests 0-shot instruction following, but I’m not sure it’s as meaningful as it could be (or testing what people think it is) when they look at a “math” score.
llm-jp-eval 1.1.0 runs very quickly (for shisa-7b-v1, with it’s speedy tokenizer, it runs in 3min on an H100) and I think it has its place, but I’ve seen most of that Japanese LLM community has decided to use it as a “gold standard” type of benchmark, and I’m not sure that everyone realizes what exactly a good score does or does not mean. Some thoughts on improving it:
While NLP performance is and important aspect for LLMs, randomly clicking through responses, I see for many models, the score reflects formatting as much as performance. I think the instructions/prompts probably need to be improved, along with few-shotting.
I believe that templating is defintely an issue and I think that moving forward, everyone should be supporting a model’s chat_template if provided in the tokenizer. I think there probably needs to be some thought as well as for whether JA language models are supposed to reply to JA questions in EN or not… Rather than exact match, maybe logprob is the way to go, like what lm-eval does?
Of course, all of these tests have train sets available, and you could train on them (we threw the train sets into ultra-orca-boros-en-ja-v1 and found it improved our overall JA performance, but when used as the primary sft, it actually obliterated all general performance (eg basic Japanese coherence, ability to respond in more than one word answers) when I tested their original 1.0 “jaster” fine tunes of models.
llm-jp-eval continues to iterate, and it looks like with 1.3.0, they’ve been adding wiki and other comprehensions tests, but without moving to multiple choice logprob or oracle/llm-as-judge, well, maybe something to revisit. Here’s some more information (and their own leaderboard) from the llm-jp-eval team.
Anyway, was a bit surprising when I started digging in today, so just thought I’d share.
BTW, JA MT-Bench has its own problems. Non-JA trained models sometimes score surprisngly well on it (GPT-4 as judge). Well, running some simple JA detection code, shows that some of the highest scoring models are simply not outputting Japanese:

~80% is the cutoff for whether it’s actually replying in Japanese or not.
Note for those looking to run similar testing, I used a dead simple (but good enough for rough cut) heuristic:
def is_japanese_char(char):
# Check if the character falls within the Japanese Unicode codepoint ranges
return any([
0x3040 <= ord(char) <= 0x309F, # Hiragana
0x30A0 <= ord(char) <= 0x30FF, # Katakana
0x4E00 <= ord(char) <= 0x9FFF # Kanji
])