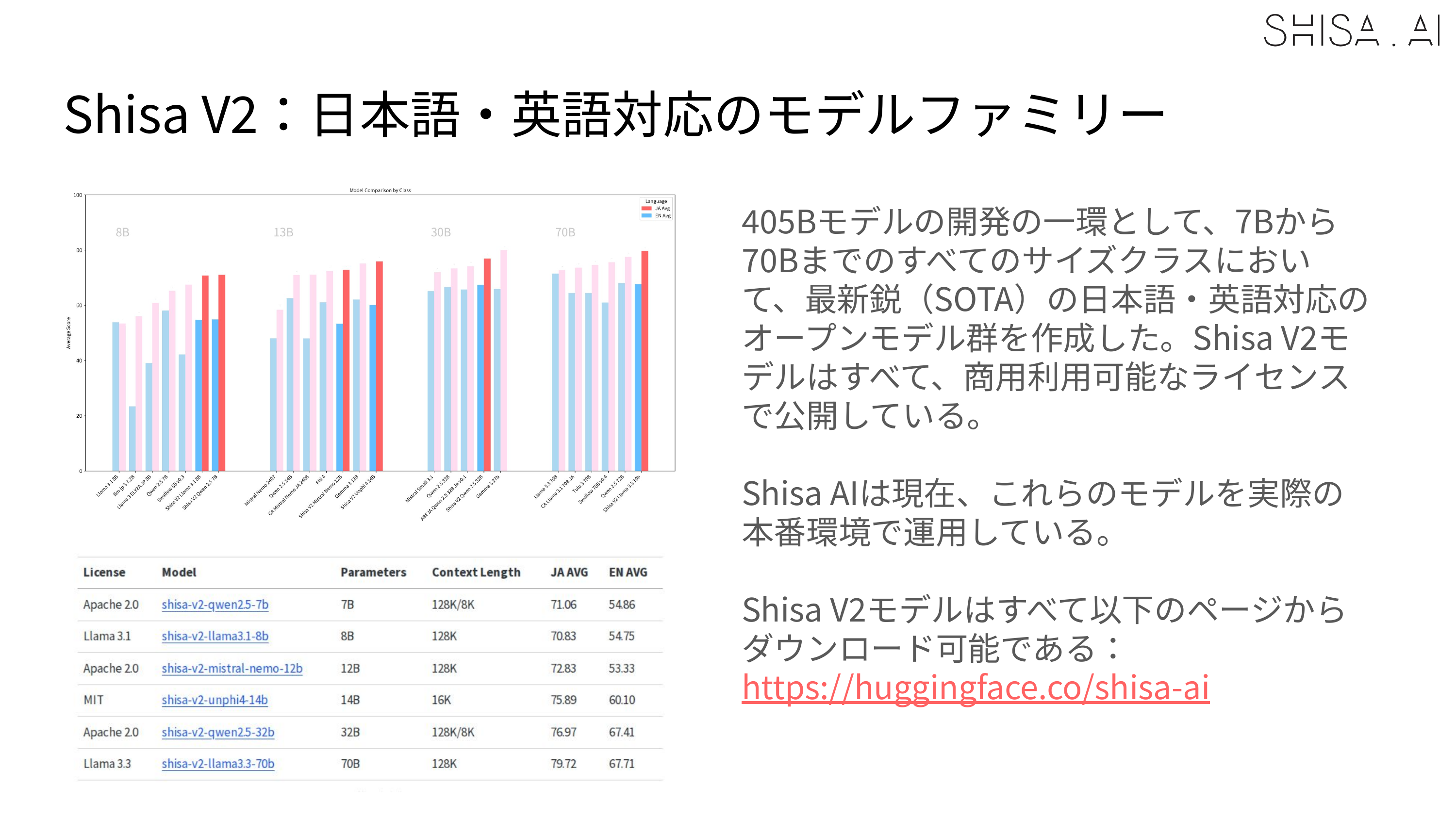
We are incredibly excited to announce one more addition to the Shisa V2 family of open-source, SOTA JA/EN bilingual models: Shisa V2 405B.
📢 お知らせ:日本語のプレスリリースはこちら → Shisa.AI、国産モデルで最高性能を誇る多言語対応LLMを開発
より詳しい技術解説やプレゼンテーションについては、概要レポート(Overview Report)をご覧ください。

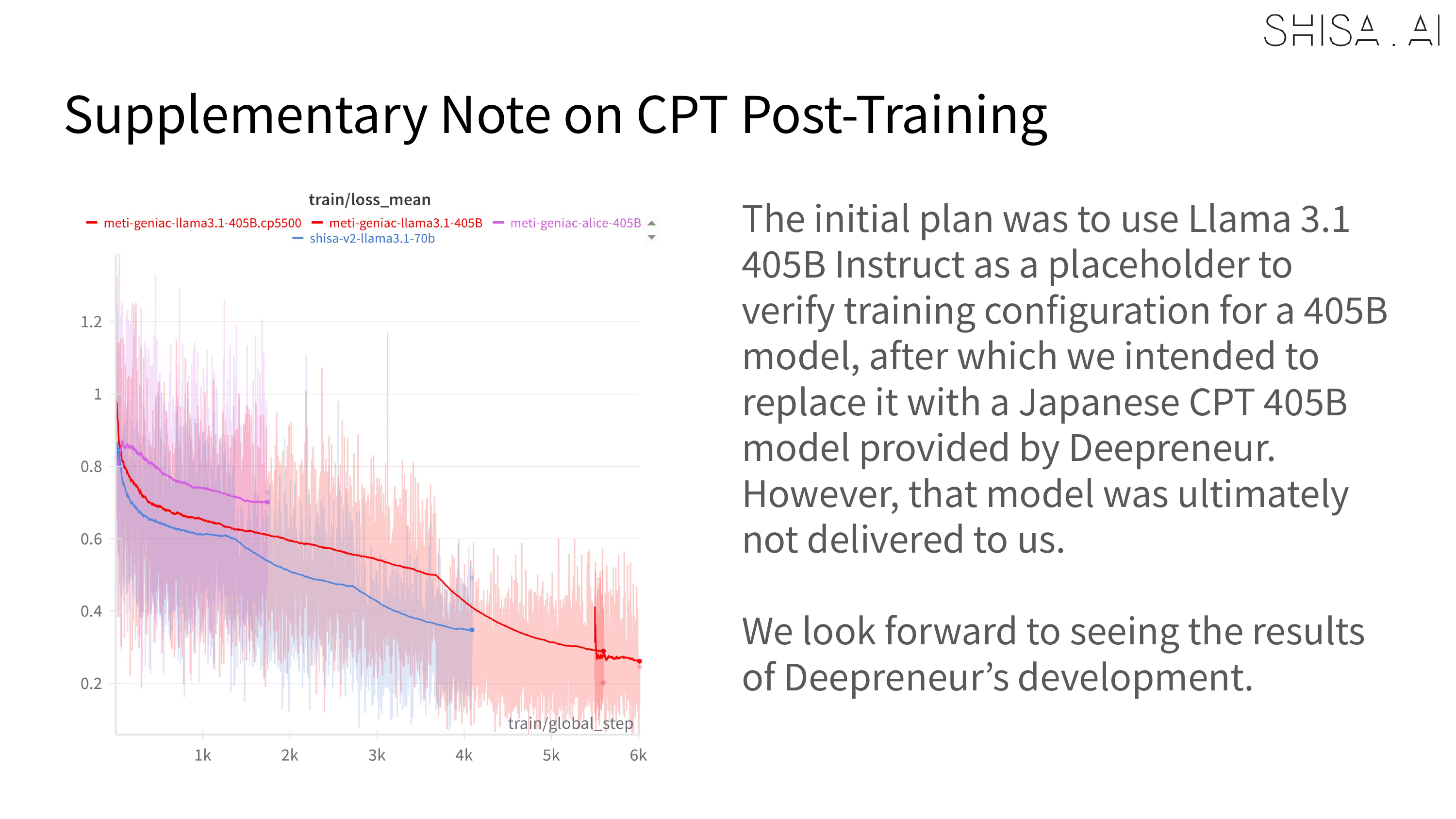
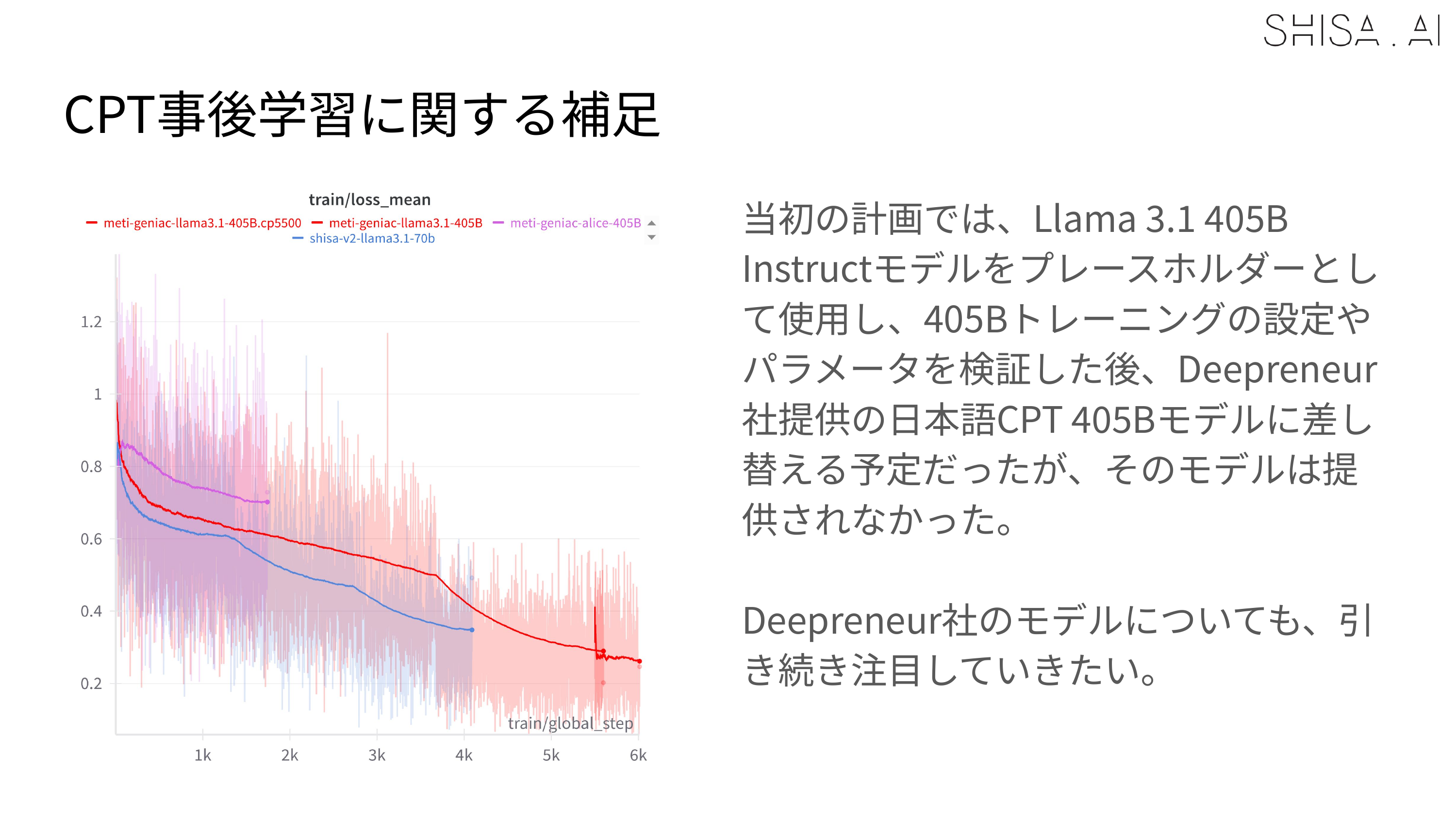
Llama 3.1 Shisa V2 405B1 is a slightly special version of our Shisa V2 model family. First, as the 405B indicates, it is massive. Using Llama 3.1 405B Instruct as the base model, it required >50x the compute to train vs. Shisa V2 70B. And while it uses the same Japanese data-mix as the other Shisa V2 models, it also has additionally contributed KO and ZH-TW language data blended in, making it more explicitly CJK multilingual.
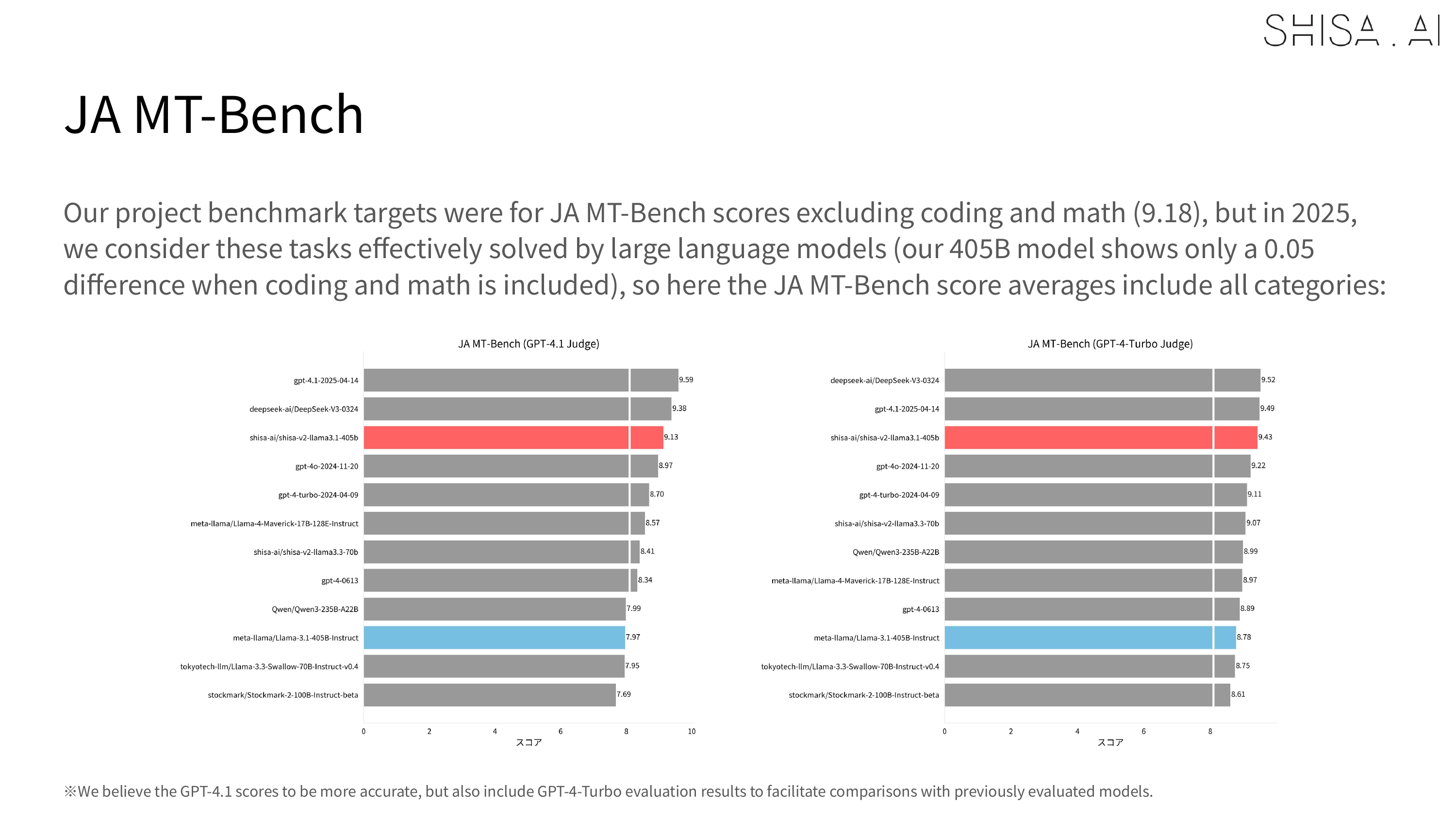
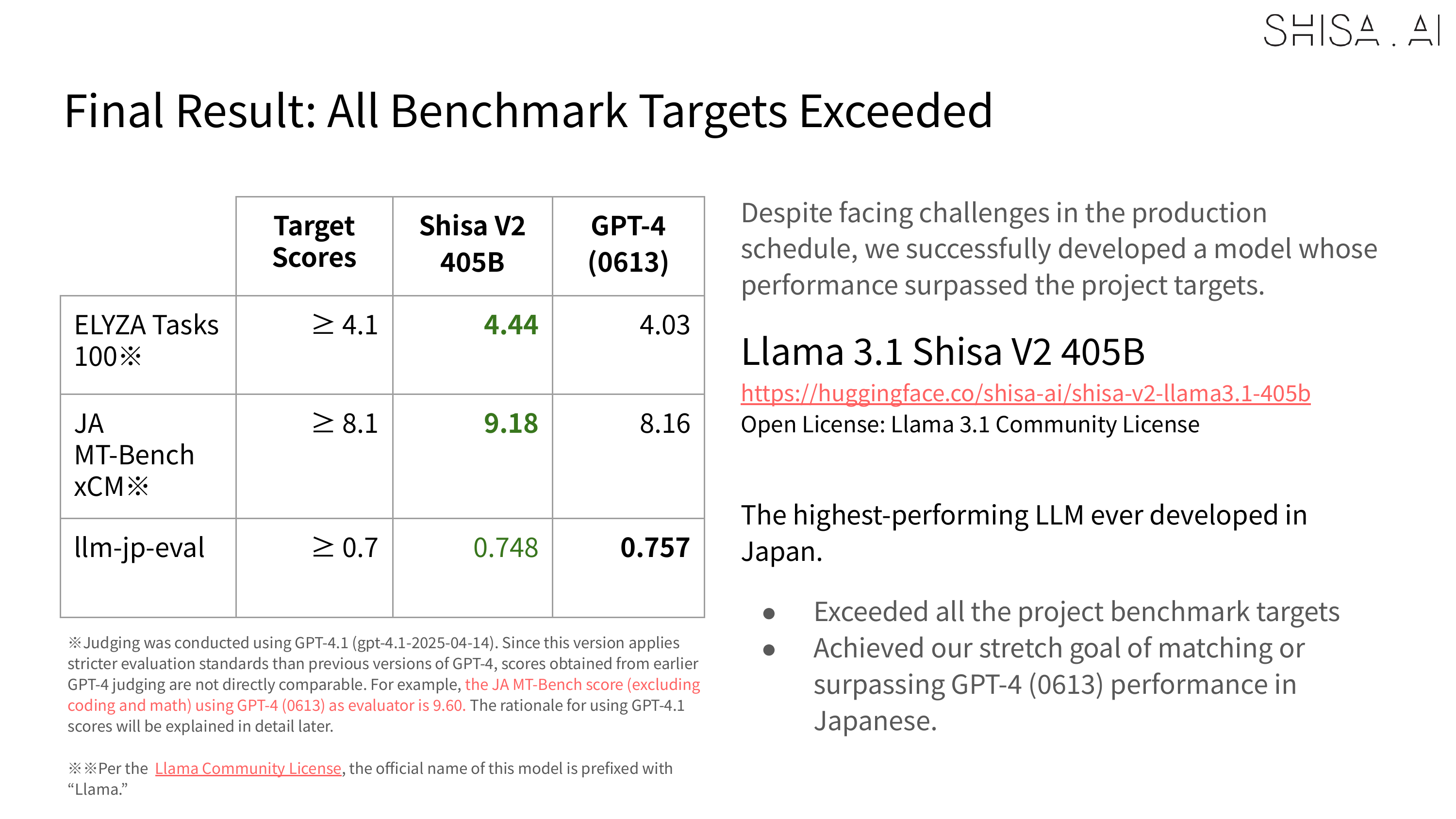
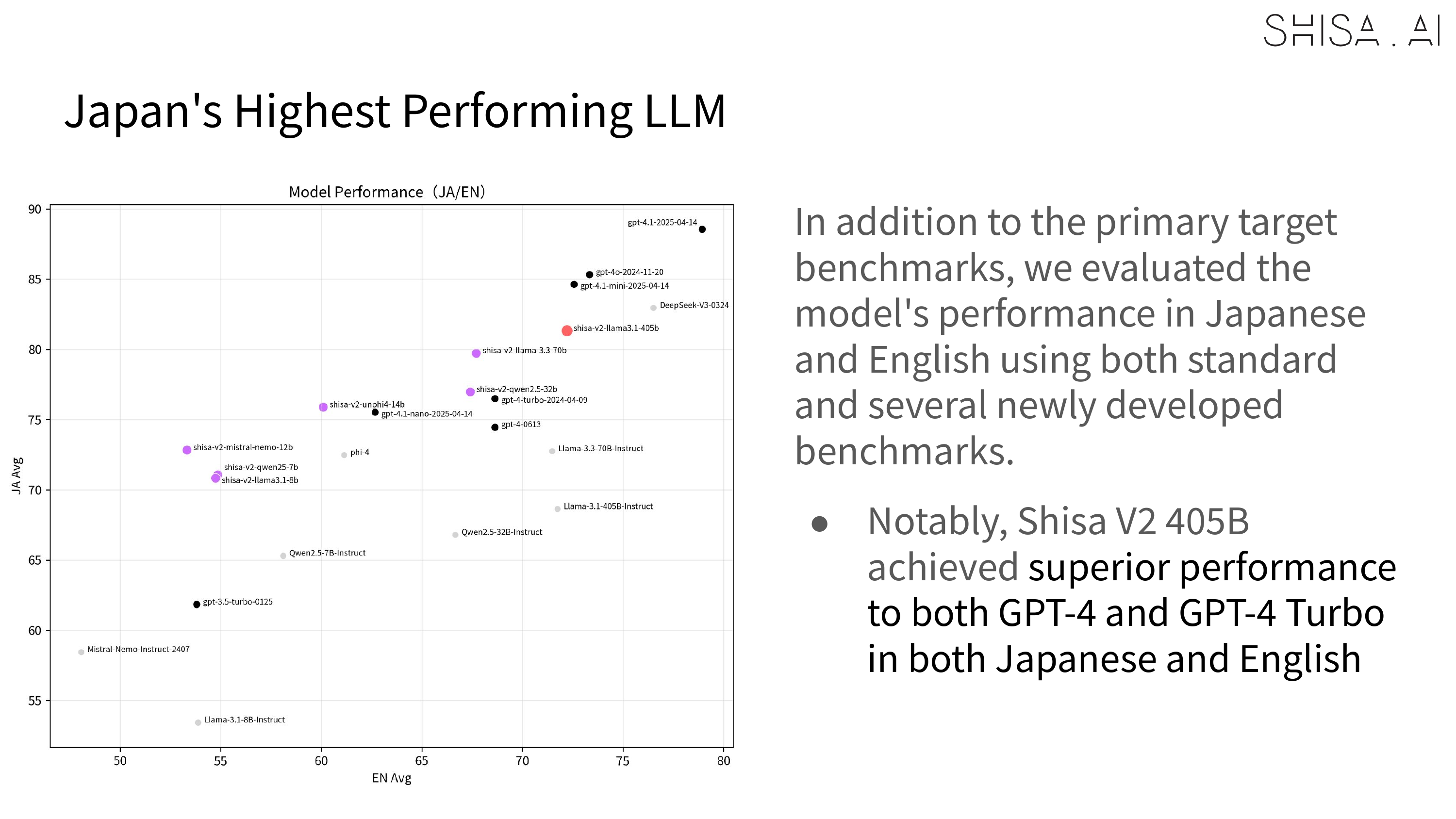
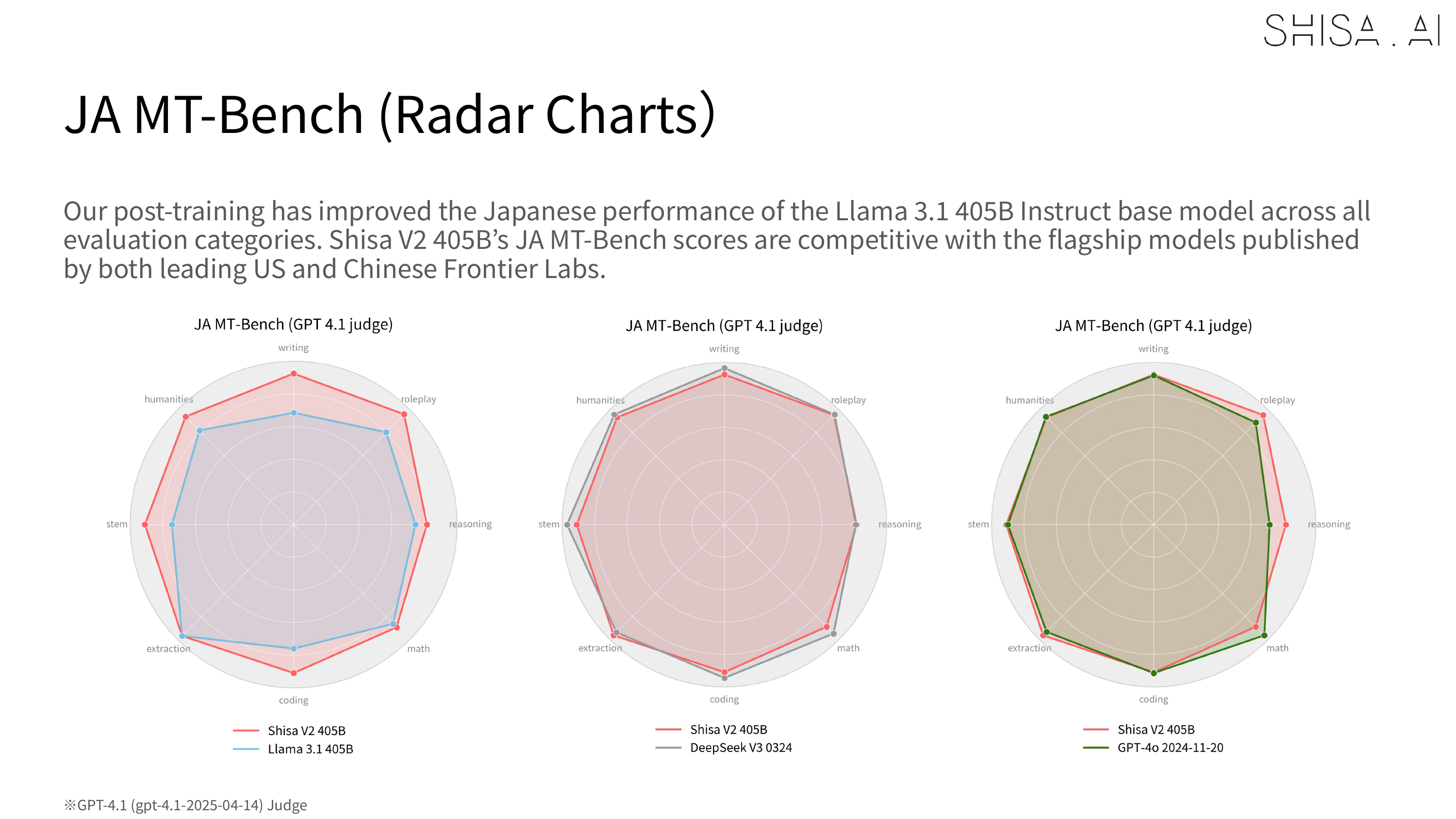
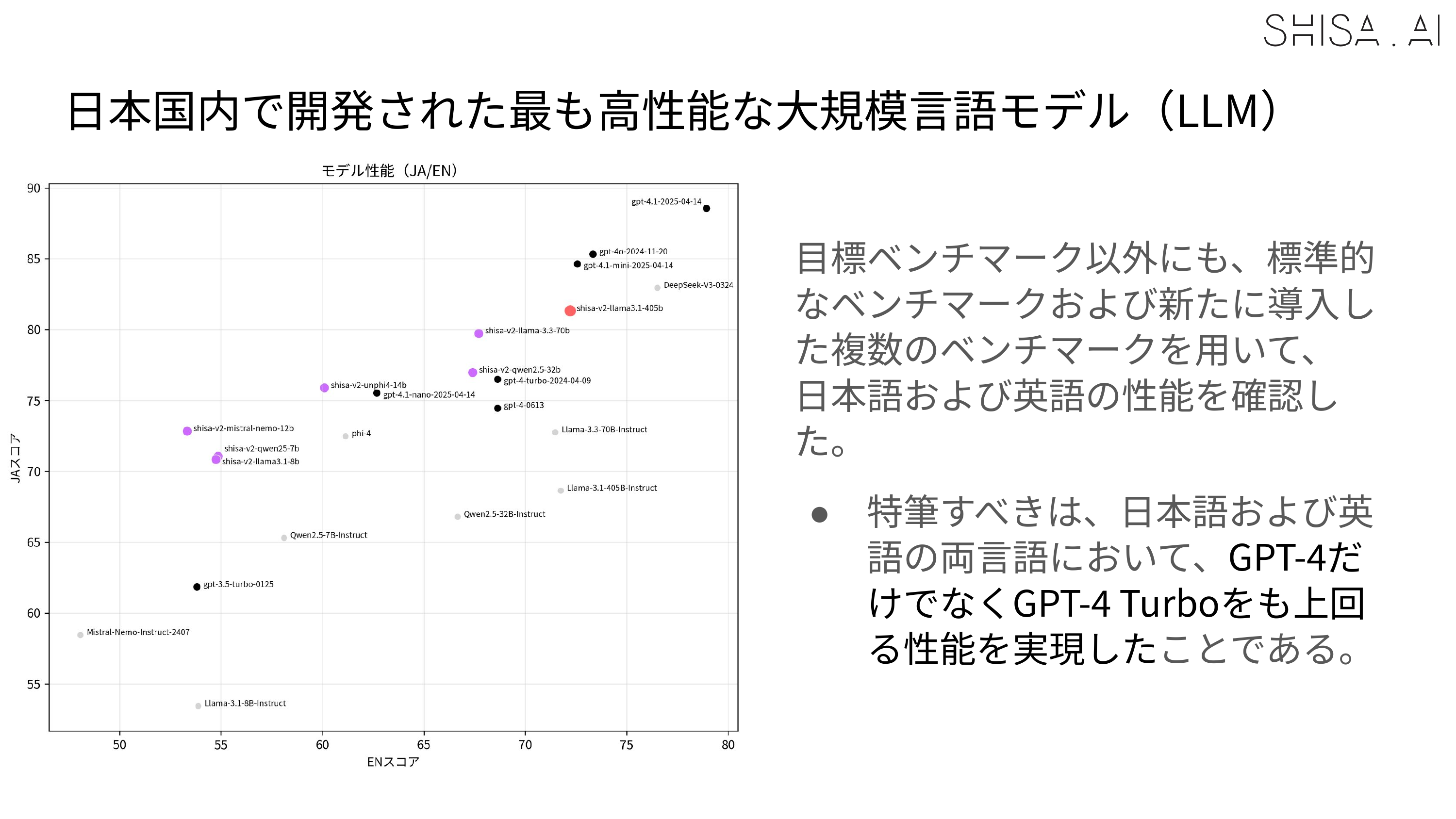
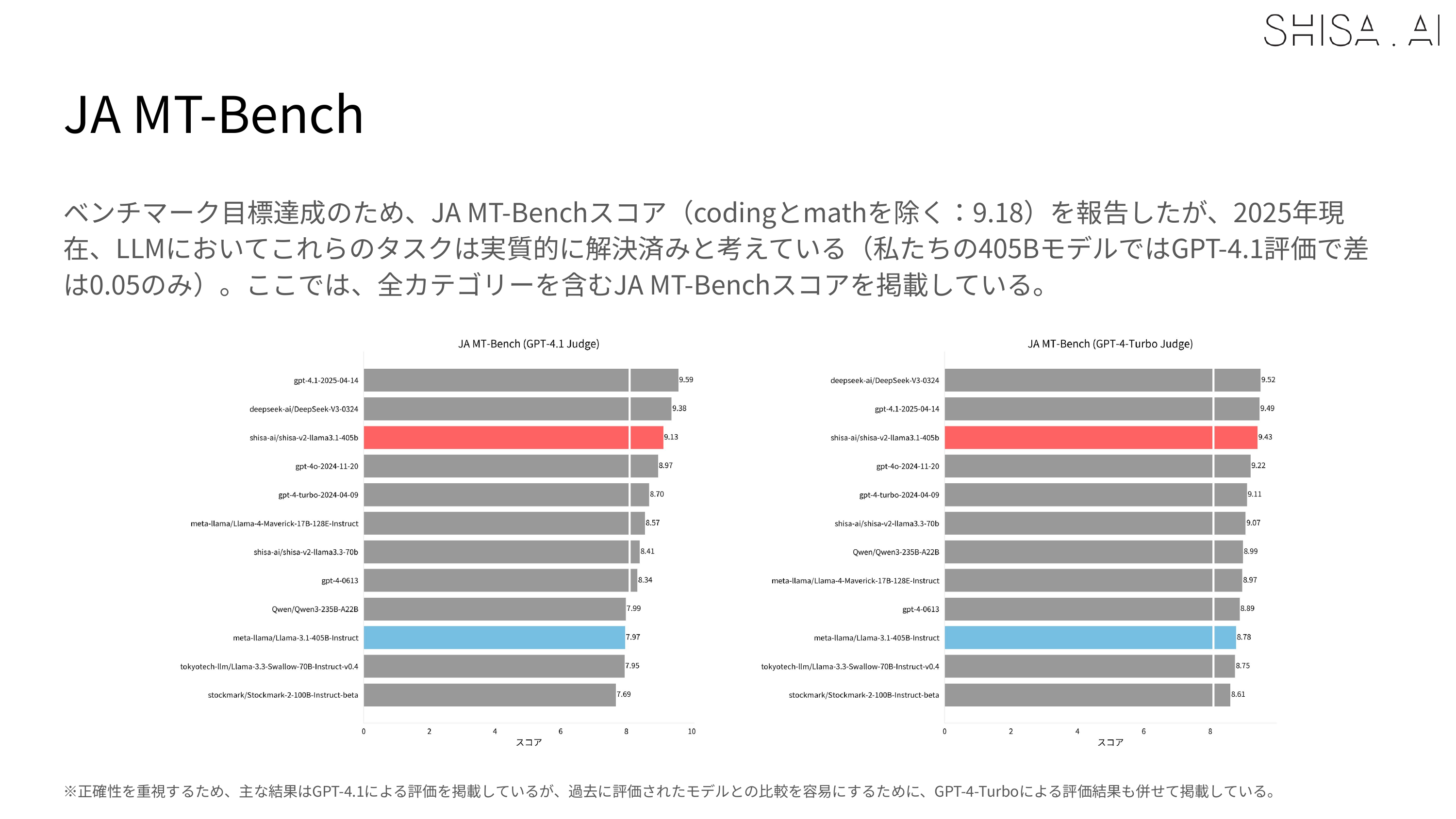
Most notably, Shisa V2 405B not only outperforms GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our JA/EN eval suites, but also goes toe-to-toe with the latest flagship models from US and Chinese labs like GPT-4o (2024-11-20) and DeepSeek-V3 (0324) in Japanese industry-standard benchmarks like Japanese MT-Bench.
Based on the evaluation results, Shisa V2 405B is the highest performing LLM ever trained in Japan, and we believe that our results help demonstrate how even smaller Japanese AI labs can excel on the global stage.
Sovereign AI
There’s been a lot of talk recently about Sovereign AI, the ability for nations to develop and run their own AI systems. Interestingly, here at Shisa.AI, we’re actually all immigrants who have actively chosen to make Japan our home. Although we were drawn here for different reasons, all of us share a deep appreciation for Japanese culture, language, and the other aspects that make Japan a unique and wonderful place.
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
Benchmarks/Evals
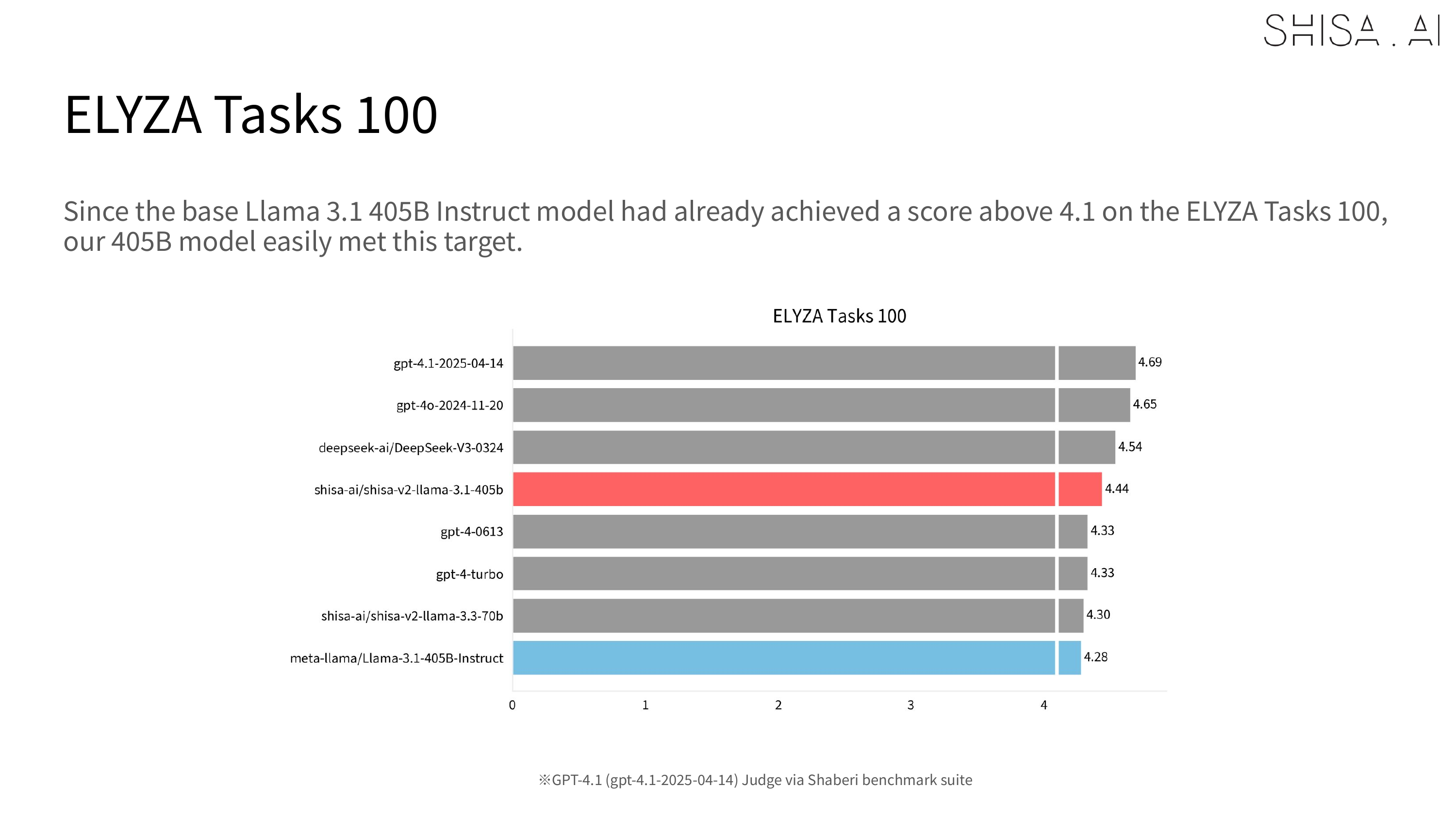
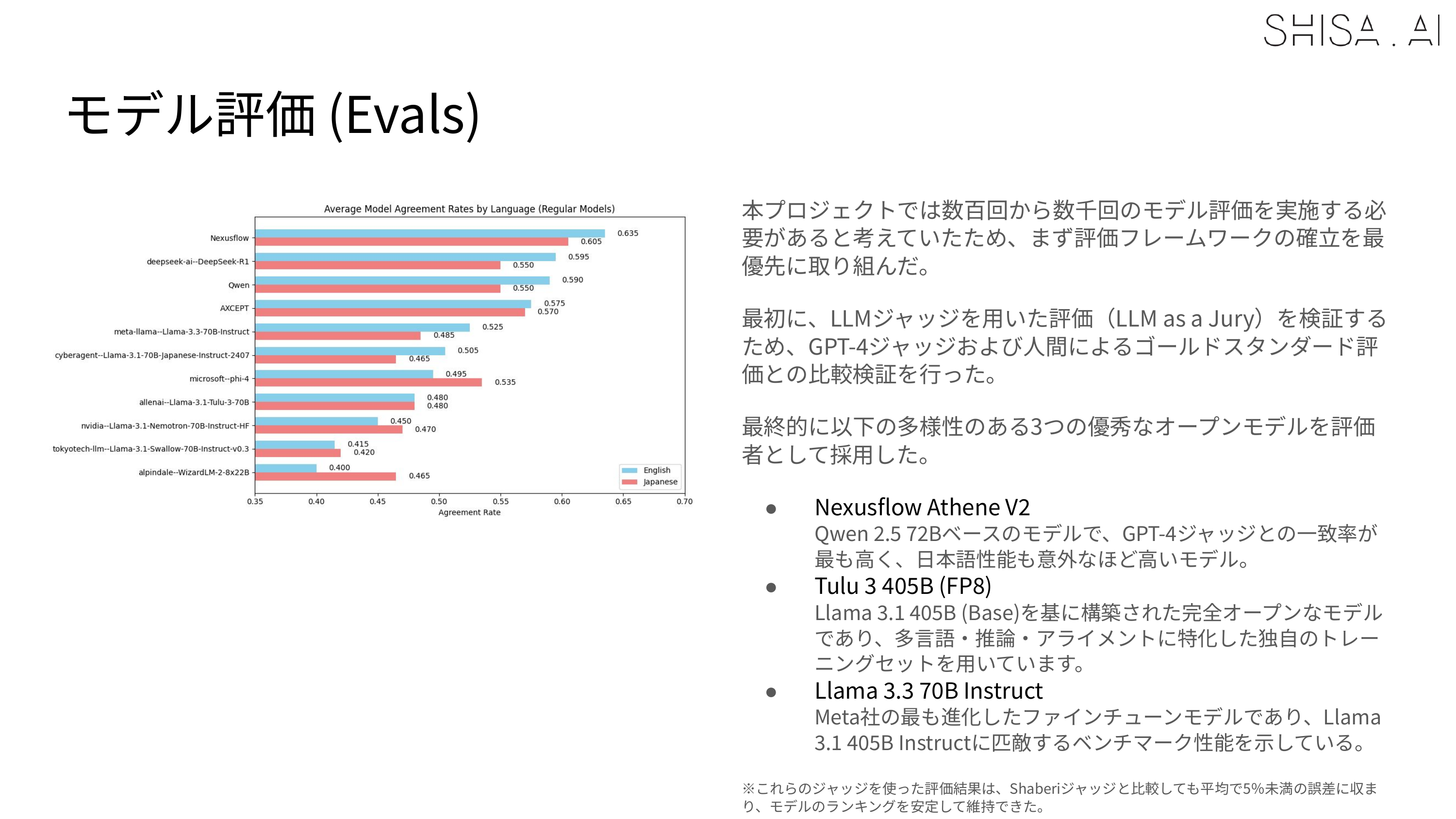
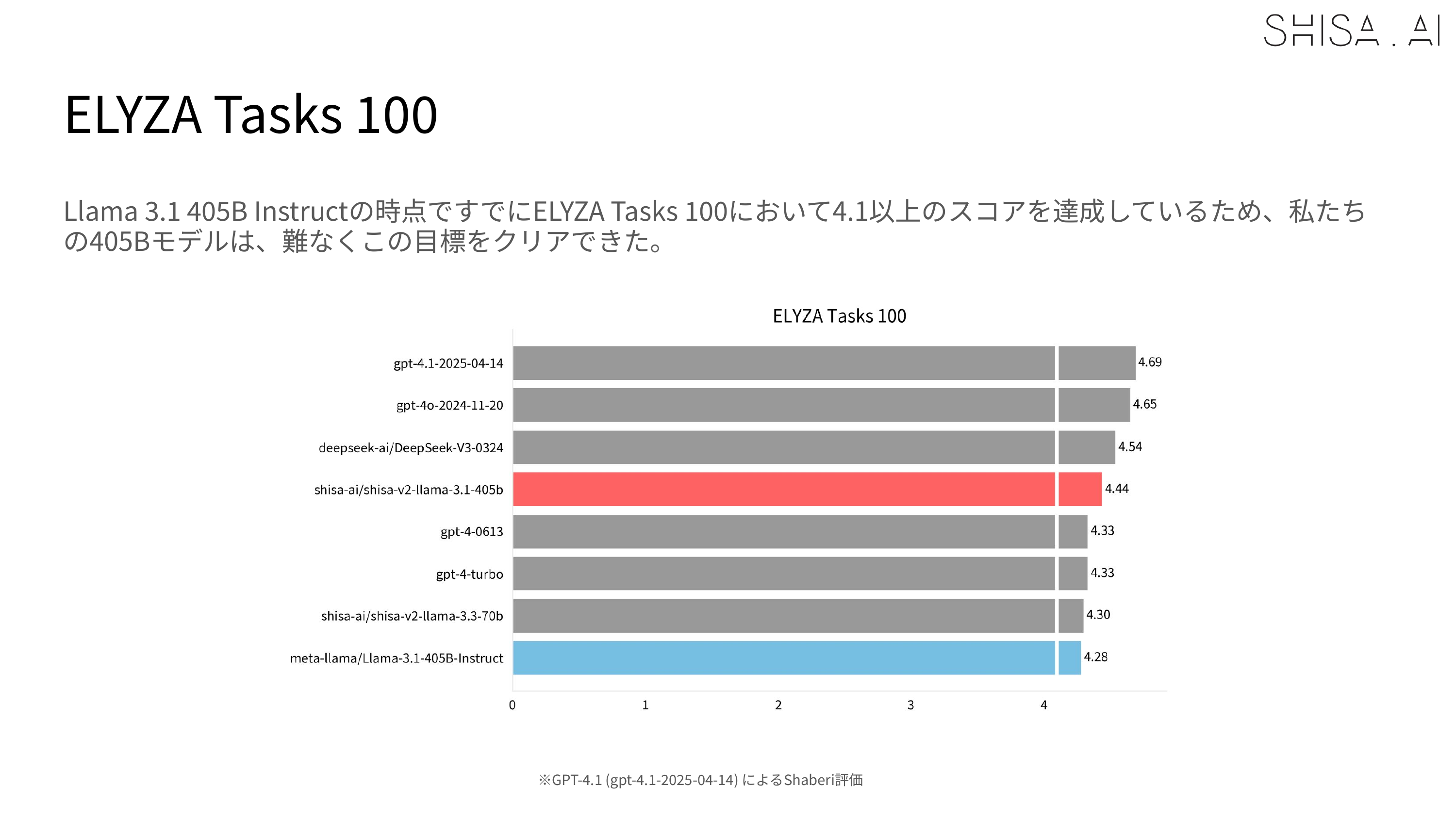
We ran hundreds of experiments building our Shisa V2 models, and we created a custom multieval framework to automatically run a diverse set of standard Japanese (ELYZA Tasks 100, JA MT-Bench, Rakuda, Tengu-bench, llm-jp-eval) and English (MixEval, LiveBench, IFEval, EvalPlus) evals to keep our model development on track.
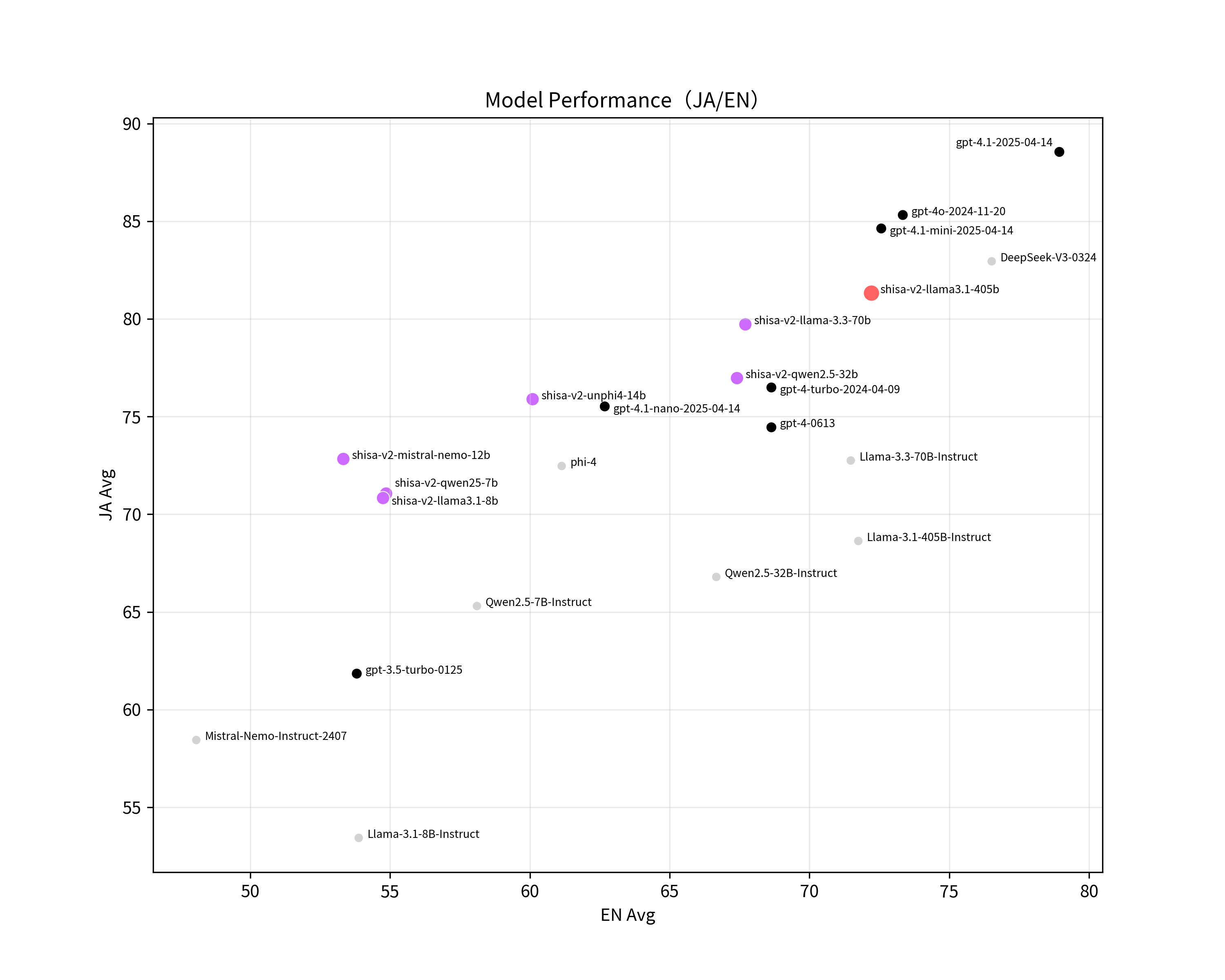
Below we show a condensed table of results (with GPT-4.1 as LLM-Judge) comparing Shisa V2 405B to the strongest models we tested, along with the original Llama 3.1 405B Instruct base model and shisa-v2-llama3.3-70b for reference.
| Model | JA Avg | EN Avg | Shaberi Avg | MixEval |
|---|---|---|---|---|
| gpt-4.1-2025-04-14 | 88.55 | 78.94 | 9.35 | 0.69 |
| gpt-4o-2024-11-20 | 85.32 | 73.34 | 9.27 | 0.67 |
| deepseek-ai/DeepSeek-V3-0324 | 82.95 | 76.52 | 8.70 | 0.67 |
| shisa-ai/shisa-v2-llama3.1-405b | 80.49 | 71.63 | 8.72 | 0.71 |
| shisa-ai/shisa-v2-llama-3.3-70b | 77.36 | 67.71 | 8.39 | 0.59 |
| gpt-4-turbo-2024-04-09 | 76.49 | 68.64 | 8.16 | 0.61 |
| gpt-4-0613 | 74.45 | 68.64 | 8.16 | 0.61 |
| meta-llama/Llama-3.1-405B-Instruct | 72.39 | 71.75 | 7.77 | 0.67 |
The full table with all of our scores is available on the Shisa V2 405B model card.
While EN language evals like MixEval were explicitly designed to reflect real-world usage (0.96 correlation with Arena scores), we found that the commonly used Japanese evals simply did not measure many of the downstream use-cases that we care about.
Over the course of model development, we created several new evaluations to help us measure performance on these tasks:
- shisa-jp-ifeval: Inspired by IFEval, but evaluating instruction-following abilities specific to Japanese grammar and linguistics (formally verified)
- shisa-jp-rp-bench: Assessing performance on Japanese role-play and character/persona-based multi-turn conversations based on Aratako’s Japanese-RP-Bench (LLM judge)
- shisa-jp-tl-bench: Testing Japanese-English translation proficiency (LLM judge, BTL pairwise comparison with logistic transformation scoring)
The latter we found to be an especially useful ranking method as a “razor” for separating out performance differences between closely performing ablations. By using a fixed set of diversely performing models, we were able to generate stable and fine-grained scoring which accurately reflected true comparative performance between models. We will be publishing additional details along with open-sourcing the benchmarks themselves for the benefit of the broader Japanese LLM community soon.
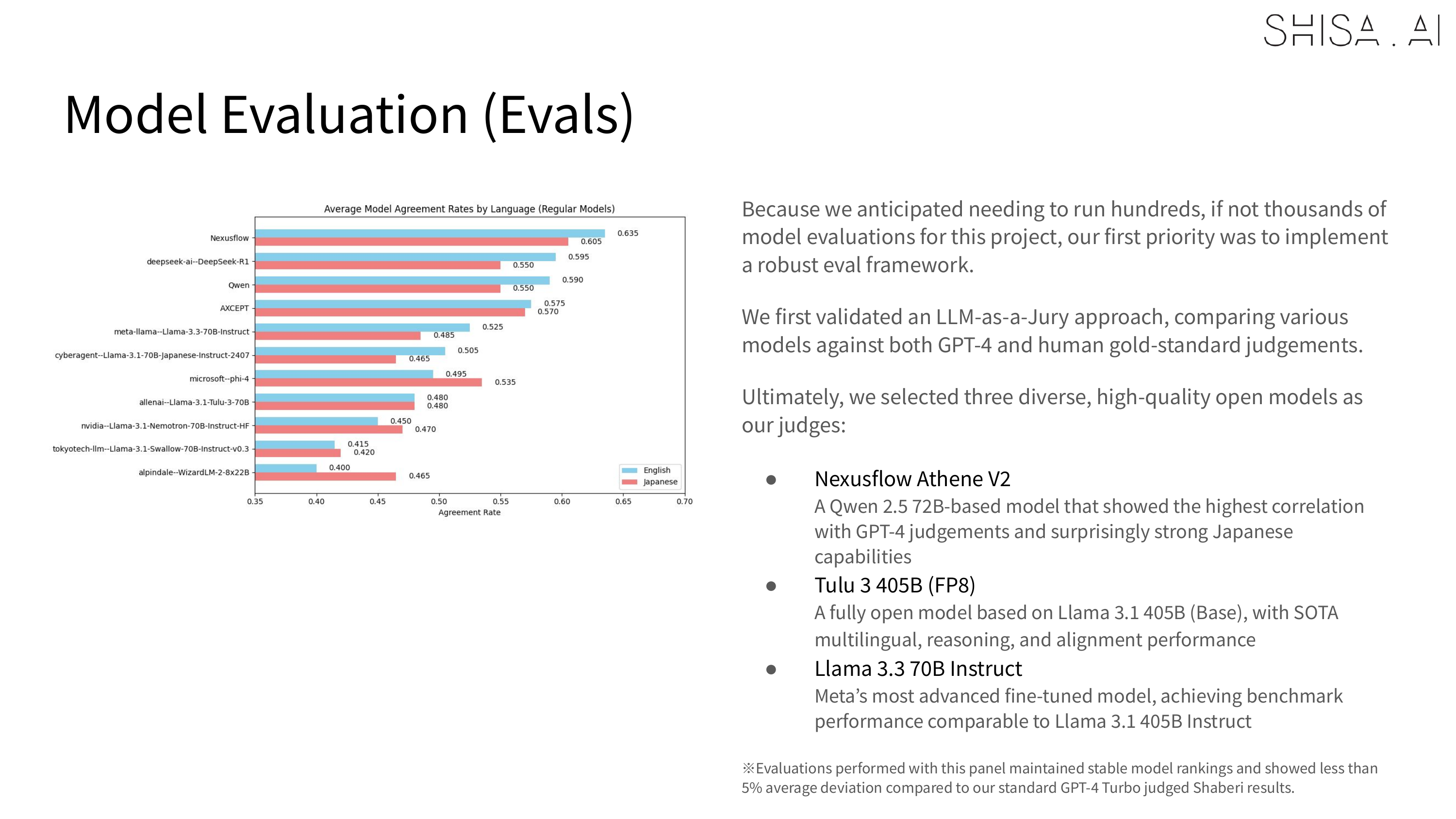
LLM as a Judge
From the outset, we knew that we would need to run hundreds, if not thousands of model evaluations for this project, so beyond implementing a robust set of evals and eval framework, we also empirically and statistically validated an LLM-as-a-Jury approach, comparing various models against both GPT-4 and human gold-standard judgments, and ultimately selecting a panel of three diverse, high-quality open models as our judges. This panel both maintained stable model rankings, and showed less than 5% average deviation compared to our standard GPT-4 Turbo judged Shaberi results.
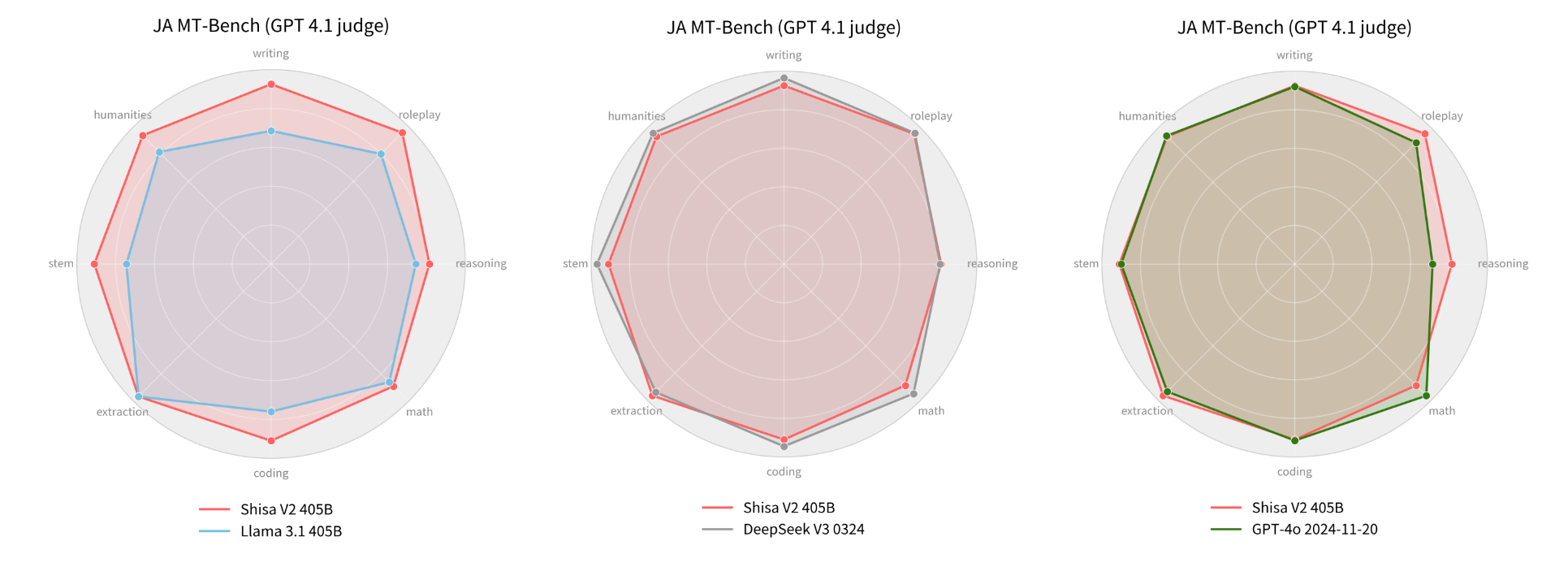
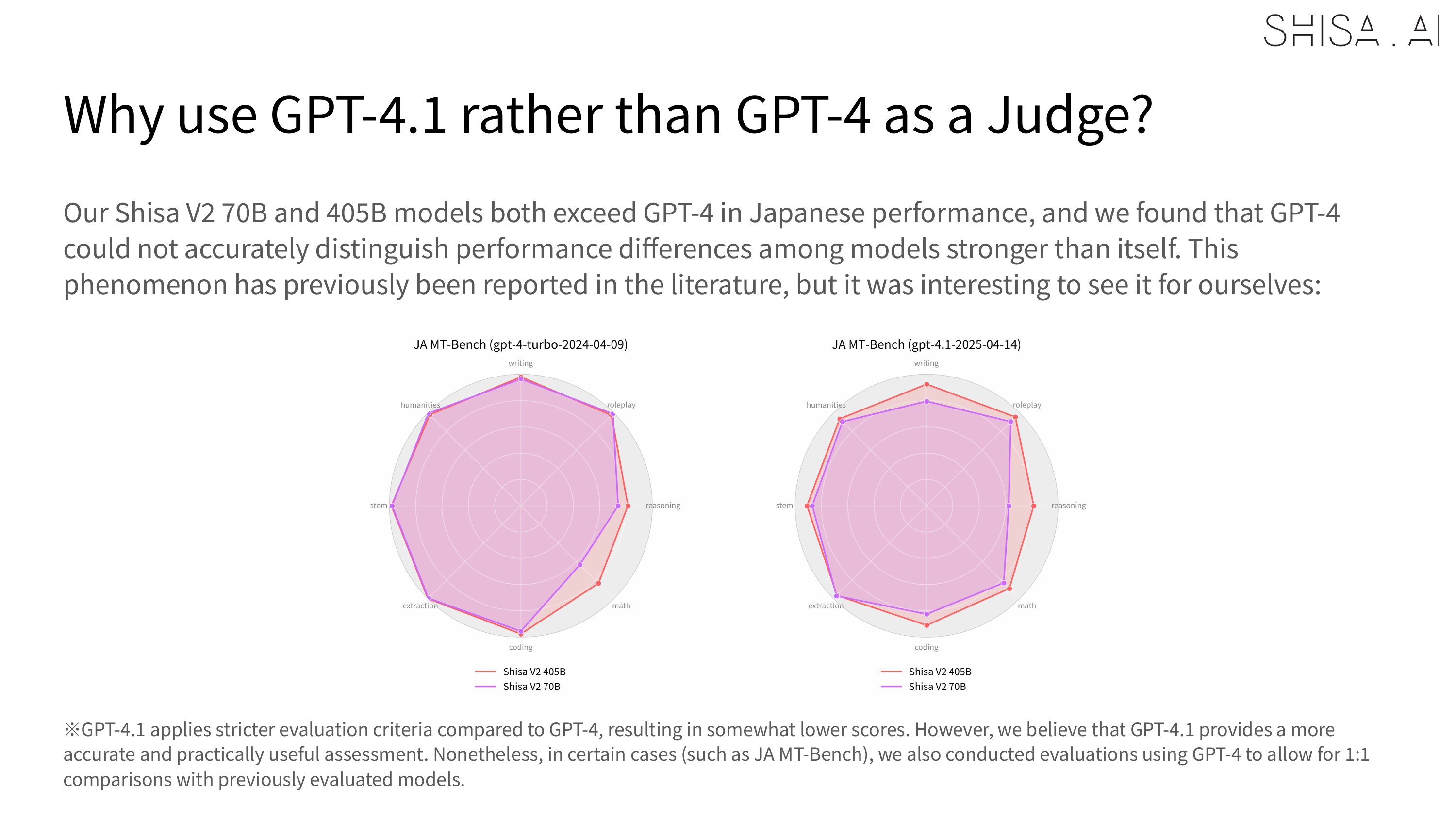
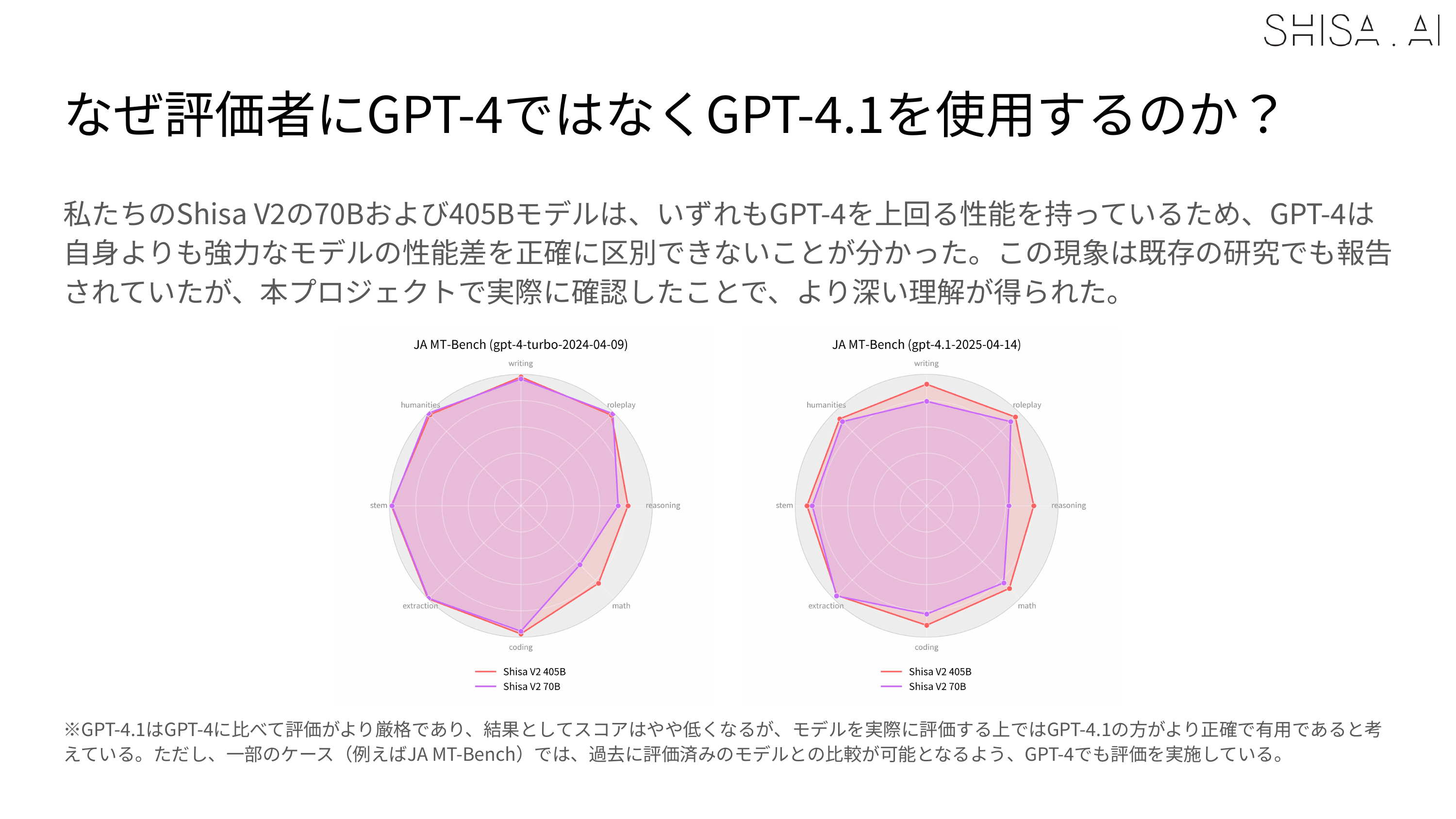
However, one of the limitations we discovered, which aligns with similar observations made in recently published literature, is that we found that weaker models like GPT-4 or our LLM-as-a-Jury panel were less able to accurately evaluate stronger models like Shisa V2 405B. For example, in our JA MT-Bench testing, GPT-4 Turbo was not able to distinguish scoring between our 70B and 405B in most categories, while GPT 4.1 was:
Regardless of the judge, in the industry standard Japanese MT-Bench, we’re happy to report that Shisa V2 405B not only leaps past all the previous top models from Japan (including our own Shisa V2 70B, of course), but is also competitive with some of the best models in the world.
One last thing that we would like to mention about evals is that we took great care with our Shisa V2 datasets to minimize contamination and avoid “benchmaxxing.” Besides using a diverse set of evals, we also developed brand-new Japanese evals to test specific real-world downstream use-cases and we believe that our improved scores accurately reflect improved model capabilities. Our goal is, ultimately, to make useful models, and benchmark results should ideally simply act as a guide to help us get there.
Data, Data, Data
It should come as no surprise that the single most important factor in improving our model performance was by improving data quality.
While we took some time chasing down some of the most intriguing new training techniques from arXiv papers (most failed to replicate for us), what worked best in reliably improving model performance, and the best “bang/buck” in terms of time/resources, was in simply focusing on improving our datasets.
When we trained our first Shisa models, we discovered that most Japanese open models were running their final post-training on extremely flawed datasets and did our best to widely share our findings. Although the situation has improved dramatically in the past year, we still believe there is a big quality gap, especially in multilingual datasets, between open and closed-source models, and we believe that this is the highest impact contribution that can be made to the community.
Shisa has always been about synthetic data, and for Shisa V2 we pushed that further than ever with extensive filtering, rating, annotation, and multi-generation from multiple SOTA open-models. Since our focus is multilingual, we also experimented with different approaches for native language generation (translation, prompting, etc), and also with different language pair ordering and curriculum learning while training.
The results were not always intuitive. One of our experiments involved pairwise training - we expected that pairwise training of matched multilingual samples would give better results, but in the end simple random shuffling worked better!
Early on in our development, we were also surprised to find that additional refinements of our original Shisa V1 dataset seemed to almost always outperform adding or swapping in other high-quality public/community datasets. While we did eventually find the right mixture of additional datasets to create to fill in specific performance gaps, over the months, we came to accept that the Shisa V1 dataset was simply even better than what we had given it credit for. And, after our refinements, the Shisa V2 version is one of, if not the, best core JA/EN SFT dataset currently available. Our final Shisa V2 dataset is a drop-in replacement for the original Shisa V1 dataset (so retains the now, slightly-dated ShareGPT format), and it is available for download under an Apache 2.0 license.
Based on our experience, having now trained a huge variety of leading open base models from 7B to 405B parameters in size, we believe that this SFT dataset can be applied to improve the Japanese language capabilities of practically any base model (without negatively impacting English performance).
Also, while this was less relevant for the approach we took with Shisa V2’s synthetic data, I do want to point out that copyright laws for AI training in Japan are much simpler than in many other jurisdictions - in almost all cases, all works are permitted to be used for the purposes of AI training.
Our final Japanese data mix we developed:

Training Details
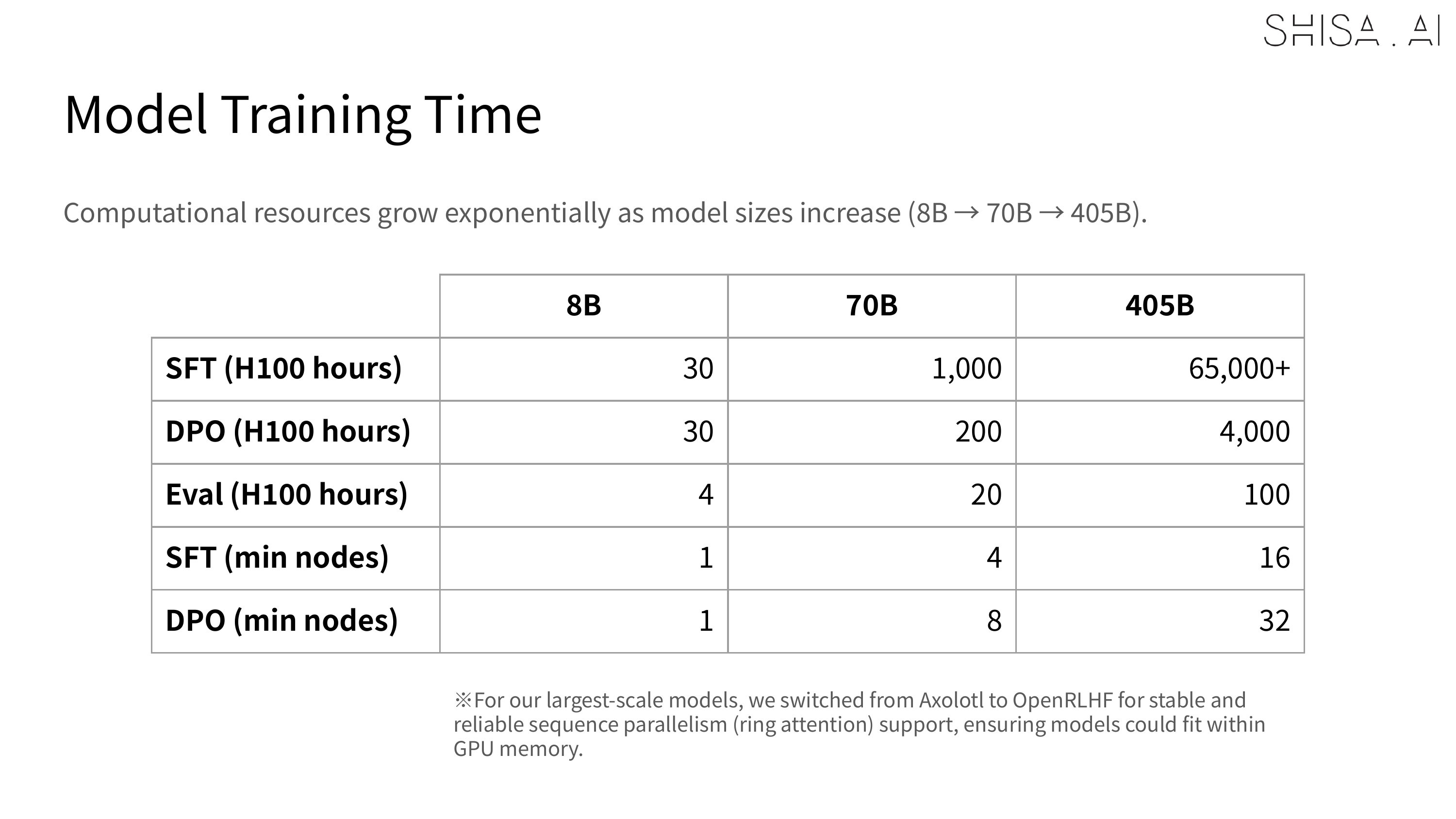
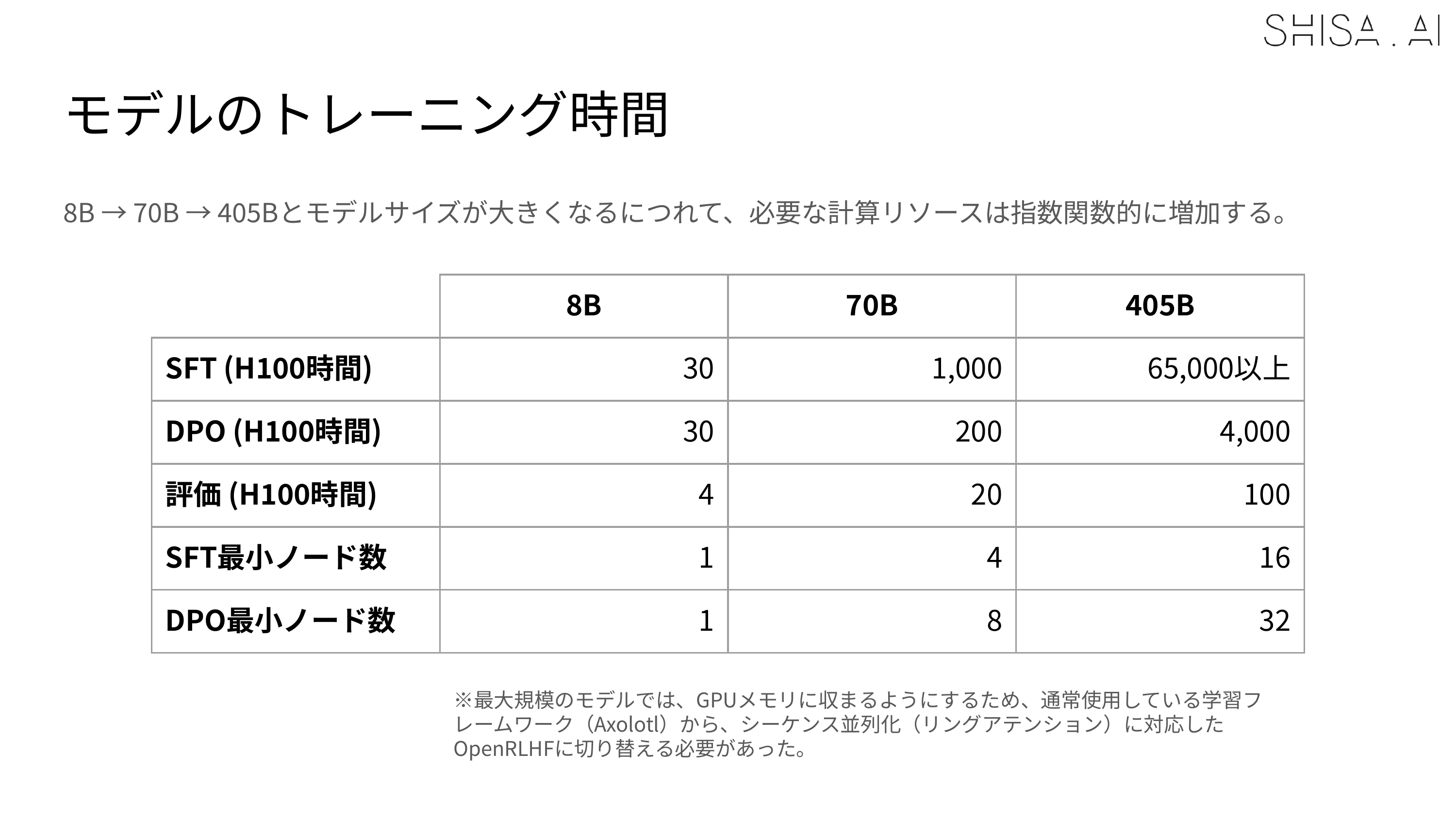
The compute for training Shisa V2 405B was generously provided by Ubitus K.K. and was significantly more resource-intensive compared to our other Shisa V2 model training.
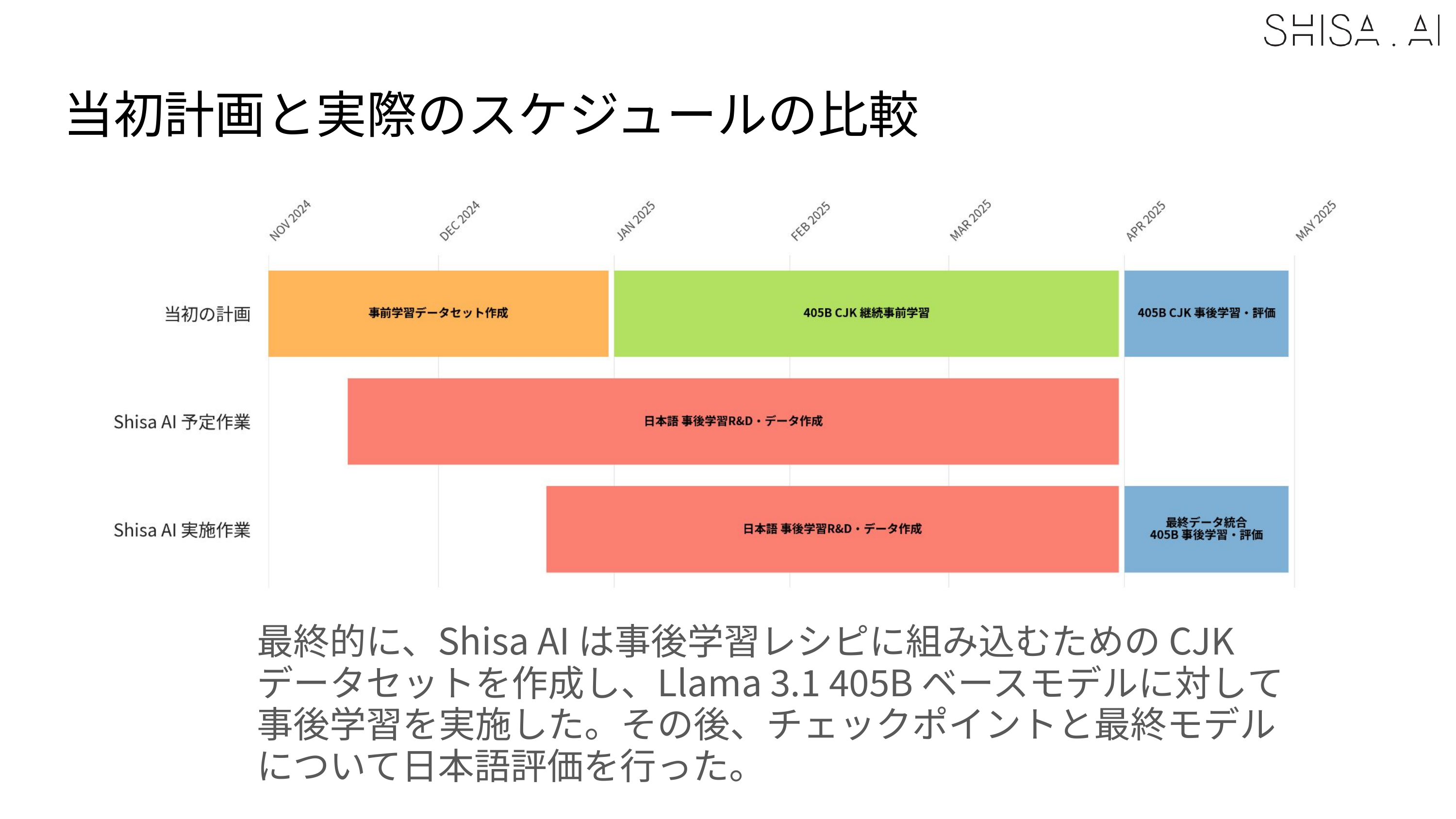
While we validated that 16 H100 nodes could be used to SFT a 405B model, to meet deadlines our final training expanded to a 32 H100 node (256 GPU) Slurm cluster. For SFT, 30 nodes (240 H100 GPUs) were used for training, with 2 nodes allocated for continuous evaluation of checkpoints. The DPO was trained on all 32 H100 nodes (256 H100 GPUs) and always crashed, even after many attempted optimizations at 30 nodes. Overall training time for the final 405B model was approximately 65,000+ H100 hours for the SFT and 4,000 H100 hours for the DPO over the course of about 2 weeks in April 2025. As a point of comparison, training Shisa V2 70B took only 1200 H100 hours for SFT+DPO.
There are very few teams that have publicly done full-parameter fine-tuning of the Llama 3 405B model (we corresponded with two of the teams that did, AI2 and Nous Research during the course of our development), and there were a number of unique challenges that we faced. We share some of the details in our Overview Report, but plan on going into full depth in an upcoming technical report.
Try Shisa V2 405B!
Shisa V2 405B is available for download now under the Llama 3.1 Community License at our Hugging Face repository:
Of course, running the full FP16 model requires at least 800GB of memory, which is a substantial ask for most. (2xH100 nodes; 1xH100 node; 1xMI300X node, etc). We have created FP8, INT8, and several GGUF versions, but realize that even that is still a challenge to run:
- shisa-ai/shisa-v2-llama3.1-405b-FP8-Dynamic - runs on 8xH100 or 4xH200 GPUs
- shisa-ai/shisa-v2-llama3.1-405b-W8A8-INT8 - this uses the Shisa V2 dataset for calibration
- shisa-ai/shisa-v2-llama3.1-405b-GGUF - these are all imatrix quants using the Shisa V2 dataset for calibration and while not comprehensive, range from IQ2_XXS (100GB) to Q8_0 (402GB)
However, if you’d like simply chat with Shisa V2 405B, we have an FP8 version running thanks to compute generously provided by Jon Durbin and chutes.ai:
Acknowledgments
@lhl: I’ll take a small break for the “editorial we” to write a brief personal missive. The Shisa V2 research team was basically just two people, who’ve been grinding away for almost 5 months straight to make it happen. The Shisa V2 405B represents a culmination of our efforts, and of course, I’m incredibly proud of what we’ve done, especially considering both the other commitments we’ve had as a growing startup, and some of the out-of-the-ordinary behind-the-scenes challenges we’ve faced.
So, first, a big thank you to Adam Lensenmayer for his incredible contributions to this project. Adam’s linguistic expertise, tireless work ethic, and ability to roll with the punches have been invaluable. If there is ever anyone who undervalues or fails to recognize what you’ve done, you should know that I hold your efforts in the highest esteem, and am profoundly thankful for your hard work.
Also, a big shout-out to my Shisa.AI co-founder Jia Shen. We’ve been friends for almost 25 years, and it’s easy to both take that a bit for granted, and to forget how incredibly rare that is. He’s been both patient and supportive while Adam and I went deep into the training cave this year, letting us cook even as the day-to-day startup-life fires started to pile up. If there’s one thing that I can recommend in life, it is to find the people that you can truly count on to have your back when the chips are down.
**ahem**
Although we were a small development team, of course we didn’t do it alone. Besides the administrative support and constant cranking from Jia and the rest of the Shisa.AI team, we should again mention Ubitus for their contributions as compute sponsor of this project.
Shisa V2 405B, of course, inherits Llama 3 405B’s 30M+ H100 hours of training, so a big thank you to Meta Llama and all the teams that provide their base models to the open source community.
We also extend our thanks to all open source AI developers and researchers - without their publicly shared research, tooling, and datasets, none of our work would be possible. We hope that our own contributions will further support the broader community.
A special thanks to Jon Durbin for his work on Shisa V1 and to chutes.ai for providing additional compute for inference hosting and evaluations of the 70B and 405B models.
What’s Next?
Shisa V2 405B represents not just a technical achievement, but a statement: that with the help of the open source community, Japan can compete at the highest levels of AI development.
We will be publishing more technical details in the near future, but please take a look at the Overview Report we assembled below, while not quite training a SOTA 405B model, it was still quite an undertaking.
Also, look for more open source code and evals once we get a chance to clean some things up and get some sleep.
Now about V2.1…
Overview Report
We share a full Overview Report we have authored in both English and Japanese here:
You can also easily view them as images online:
English Version














Japanese Version















1: Per the Llama 3.1 Community License Agreement, the official name of this model is prefixed with “Llama”